Jan 24, 2024
Accurate AI Information Retrieval with Guardrails
Introduction
AI is simplifying hundreds of tasks across dozens of industries. One exciting area is information retrieval, or extracting useful information from unstructured documents. In this article, we'll show how you can use Guardrails to provide additional context to an AI engine to parse important information from free-form text with greater accuracy.
Using AI as an information parsing engine
Structured text simplifies parsing information programmatically, as it has a defined, predictable format. It's trickier to extract information from unstructured text, such as documents. Both the location and format of information may differ wildly from text to text.
But there's a wealth of value in parsing information out of unstructured text. Some scenarios include:
Parsing tax, loan, and other financial documents for digitization
Capturing critical health care information from physical forms, such as patient intake forms
Using information for comparison purchasing, such as comparing terms & conditions across credit card providers
Ideally, we want to extract this information and put it into a structured format, like JSON. That way, other applications and API endpoints can parse the information automatically, without human intervention.
Before AI, you could perform information retrieval tasks like this using machine learning systems like Amazon Textract from AWS. However, these systems required a fair amount of programming to train the underlying machine learning model to understand your document formats and how information was formatted and grouped.
By contrast, an AI engine comes with a Large Language Model (LLM) that has been trained against documents in a wide variety of formats. This means that, with a bit of coaching via prompts, we can leverage AI to act as a sophisticated parsing engine for unstructured text.
Using Guardrails for information retrieval
Ensuring accuracy with AI output can be challenging. That's particularly true when parsing unstructured documents.
Oftentimes, you may need to re-prompt the AI multiple times, clarifying your prompt instructions along the way, before you get the output you're seeking. While that might work for extracting text from a single document, it doesn't scale to processing hundreds or thousands of documents.
Guardrails automates this AI quality control process. Using either a simple specification language or the Python Pydantic library, you can set more exact parameters specifying the expected output format. Guardrails ensures the AI output conforms to this spec and handles re-prompting if it doesn't.
Let's step through how this works in practice. In our example, we'll build a simple Python application that extracts the key elements from a credit card service agreement. This includes the default interest rate, penalty rate, cash advance rate, balance transfer costs, foreign transaction fees, and other details.
Prerequisites
You will need Python 3.10 or greater installed on your system to run this code sample. You can also run it from Jupyter Notebook. You can download our sample notebook here.
Make sure to install the following Python modules using Pip:
pip install -U guardrails-ai openai numpy nltk pypdfium2 -q
This example uses OpenAI as the LLM for processing queries. Therefore, you will also need an OpenAI API key to run this code. To obtain a free OpenAI key, create an account. When asked to choose between using ChatGPT and API, select API.

From there, select your account icon in the upper right corner and then selectView API keys. SelectCreate new secret keyto generate an API key.
Finally, save the sample Chase credit card agreement to the local location data/chase_card_agreement.pdf. (This location is relative to the directory from which you will run your script or from which you started Jupyter.) This is a standard anonymous agreement that does not contain any personally identifiable information.
Load the document
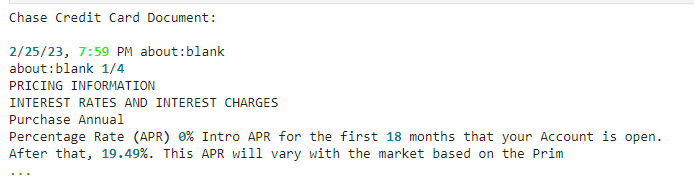
First, let's load the document we want to parse into memory. Guardrails provides utility functions for reading documents in various formats, including PDFs:
The output will be the first 275 characters of the PDF file, rendered as text:
Create a RAIL spec programmatically using Pydantic
Next, we'll create a RAIL specification. The RAIL specification is at the heart of Guardrails. It defines a prompt as well as an output format for the AI response. Guardrails enforces the specification with a family of custom validators that check whether the AI output conforms to the spec.
There are two ways to define a RAIL specification: in XML (either inline or as a separate file) or programmatically using Pydantic. Let's define one using Pydantic:
The prompt includes a number of placeholder variables. As we'll see below, Guardrails fills these in as you instantiate Guardrails objects and make calls to the LLM.
Once defined, we create a Guard object from our specification using the from_pydantic() method of the guard namespace:
guard = gd.Guard.from_pydantic(output_class=CreditCardAgreement, prompt=prompt)
If you print out the guard object, you'll see exactly what Guardrails will send to the AI engine:
print(guard.base_prompt)

The variable $(document) will be replaced by the document you want the AI engine to parse when we make the call to OpenAI below. You'll notice that Guardrails has replaced the placeholders for the output schema with a well-formatted XML document. Each return property of the XML contains a format field that specifies the expected format of that piece of data.
Wrap the LLM call with the guard
Our guard acts as a wrapper to the call to the LLM. Guardrails will fill out any remaining variables in the prompt, send the prompt to the LLM, and then verify that the LLM's feedback is correct.
Before making the LLM call, we must set the API key for OpenAI. The easiest way to do this is to define an environment variable, OPENAI_API_KEY:
See our previous article on solving hallucinations in AI to see an example of passing the API key directly at invocation time.
We now call OpenAI with our Guardrails wrapper:
The openai.Completion.create value specifies that we're invoking OpenAI's chat completion model. We use prompt_params to fill in the value of the $document value in our prompt with the text that Guardrails extracted from the PDF file.
The other parameters here are sent directly to OpenAI and are:
engine: Which OpenAI engine to use. Here, we use the company's GPT-4 engine.max_tokens=2048: Sets the maximum number of tokens (words or subwords) the generated text should contain. This is used to limit the length of the generated response. Longer responses take more computational power to process, which increases application costs.temperature=0: Controls the randomness of the generated text. Higher values (e.g., 1.0) make the output more diverse, while lower values (e.g., 0.2) make it more deterministic. Here, we're specifying complete determinism with a value of 0.
Examine the output
To see what we got back from the Guardrails-wrapped LLM call, we can print out the response like so:
print(validated_response)
You should see something like this:
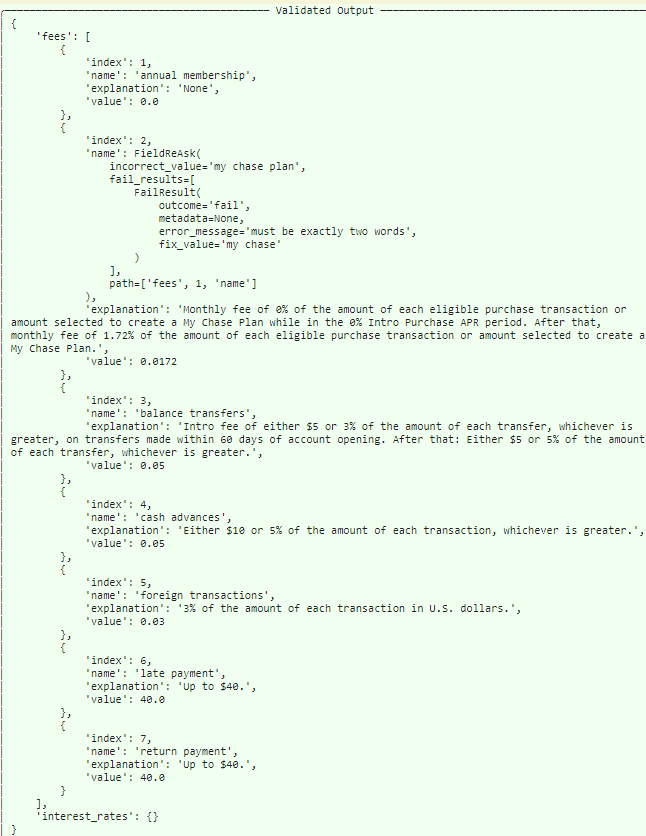
Based on our Guardrails-generated specification, OpenAI returned the information we sought in the JSON format that we requested.
How did Guardrails arrive at this final set of values? To see the full interaction between Guardrails and the LLM, we can print out the guard.state.most_recent_call.tree property:
Guard.state.most_recent_call.tree
As part of this tree, we can see that, in response to the first LLM call, the LLM returned the following output:
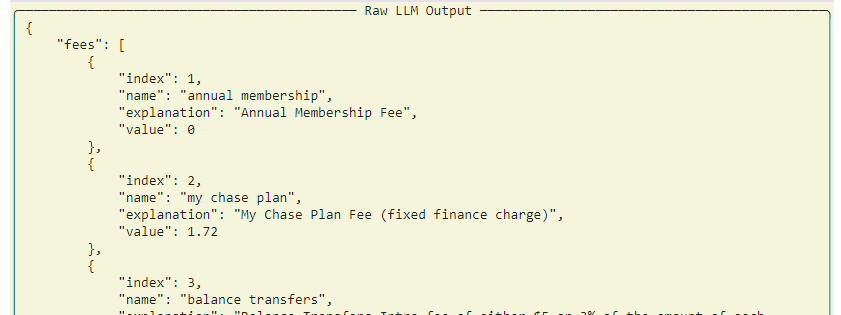
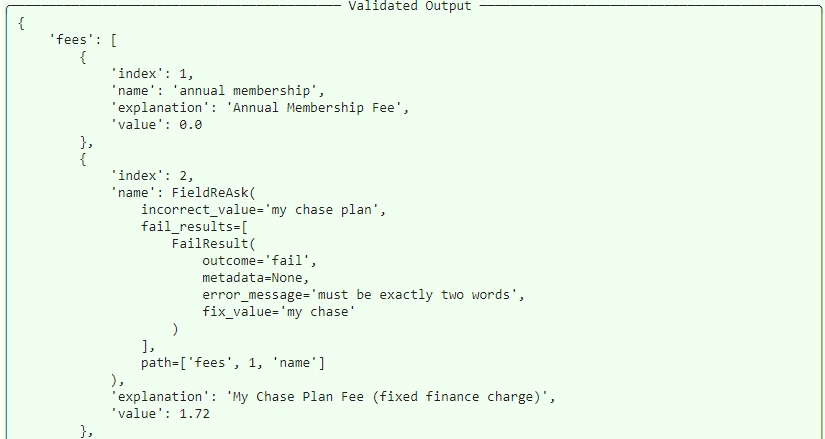
This isn't exactly correct, as we specified that the name field should only contain two words. In the second list object, it contains three. You'll see in the Validated Output section that Guardrails flags this output as invalid and marks it as needing correction. It also provides a suggested correction to help train the LLM:
Guardrails makes a second call to the LLM, enhancing the prompt to indicate that there are incorrect values and asking for a redo:

...
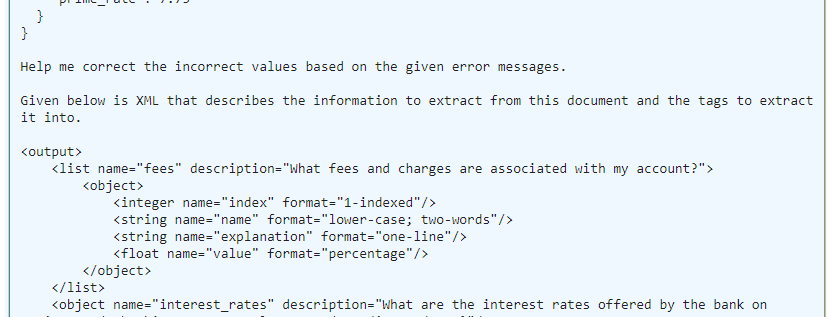
As its final output, Guardrails returns the corrected response that conforms to the model semantics we supplied.
Conclusion
Extracting key information from unstructured text into machine-readable text unlocks some important use cases in finance, health care, and other fields. Until now, building such applications was expensive and time-consuming. Using Guardrails AI, you can perform complex information retrieval that yields validated, high-quality output with a minimal amount of coding.