Feb 2, 2024
How Well Do LLMs Generate Structured Data?
Introduction
What's the best, most accurate way to generate structured data at volume? Our engineering team decided to find out in a benchmark that pits OpenAI against GPT4All. Which one produced the most accurate results?
Generating structured data
If there's one thing our applications can't get enough of, it's data. Modern Generative AI and Machine Language use cases require large volumes of data to draw accurate conclusions. However, producing this data through traditional means is expensive and time-consuming.
Large Language Models (LLMs) can help in several ways. We can use them to re-format existing data into a machine-usable format (like JSON) that fits our use case. We can even leverage them to generate new data from scratch.
We can break down structured data use cases with LLMs into the following four categories:
Synthetic structured data
Synthetic structured data is data in a machine-parseable format (like JSON) that is structurally and mathematically similar to real-world data. For example, here's a prompt we might use to an LLM to generate synthetic product orders:
Generate a dataset of fake user orders. Each row of the dataset should be valid. The format should not be a list, it should be a JSON object.
An example of output may look like this:
As I've written before, generating synthetic structured data is a great use case for Generative AI. Studies have shown that using synthetic data in analysis can be just as good, if not better, than using real-world data. It's definitely a lot cheaper to produce!
Data filtering
Take existing JSON data and return only data that matches specific criteria. Example:
Given a JSON list of 'employees', filter out only those who work in the 'Engineering' department. The output should be a JSON object with a list of 'filteredEmployees' with their 'name', 'department', and 'salary'.
Data conversion
Convert unstructured text to structured JSON data. Example:
Transform the following text into a JSON object: 'Great Expectations, a novel by Charles Dickens, was published in 1861. It's a remarkable piece of literature. Rating: 4.5'. The JSON should include 'bookTitle', 'author', 'publicationYear', 'comment', and 'rating'.
Data interpretation
Take existing JSON data and return records that match a set of complicated input criteria. Example:
Analyze the given JSON 'salesData' to identify the top 3 best-selling products. The output should be a JSON object with a list of 'topProducts' with 'product' and 'unitsSold'.
Our methodology
We wanted to see how well two popular LLMs generated structured data according to each prompt. So we created a benchmark comparing the following three models:
We chose these models based on reputation as well as pricing. While OpenAI is the market leader, API pricing factors may cap how often and at what scale you can leverage it. GPT4All is free to use, as it runs locally on your own hardware and doesn't impose any usage-based charges.
For our tests, we created 10 prompts requesting structured output in JSON, with each prompt varying in size and complexity.
We structured each prompt as follows:
We then created four styles of prompts to test the different types of structured JSON output I noted above: synthetic structured data, data filtering, data conversion, and data interpretation.
We ran these through a data pipeline and then scored the responses to all 10 prompts numerically using the following criteria:
Schema compliance. Did the LLM return the format we requested in our prompt and context? We measured this by comparing each response with an expected schema, which we evaluated using the Python jsonschema library.
Completeness. How often did the LLM return the fields we requested? For this, we used a count of the fields in the generated output.
Type accuracy. How often did the LLM return data of the type and/or format that we requested (e.g., numeric data vs. a string, length-limited strings, correct data format)? For this, we compared the actual type to the expected type?
Content accuracy. How many returned filtered records matched the criteria we provided? In this case, we compared the actual results to a pre-set list of expected results. (Note that we only applied this to the non-synthetic structured data cases.)
The results
Here are the overall results, along with a breakdown of how well each model performed in the four types of data tasks we listed above.
Overall comparison
Model name | Mean Type Accuracy | Mean schema compliance | Total incomplete items | Mean content accuracy | Mean runtime / prompt (seconds) | Total cost (USD) | Group size |
|---|---|---|---|---|---|---|---|
OpenAI gpt-3.5-turbo | 0.91 | 0.9 | 25 | 0.939 | 14.005 | 0.048 | 150 |
GPT4All mistral-7b-instruct-v0.1.Q4_0 | 0.988 | 0.933 | 0 | 0.77 | 7.117 | 0 (Free, local) | 60 |
GPT4All falcon-q4_0 | 0.82 | 0.683 | 10 | 0.341 | 6.966 | 0 (Free, local) | 60 |
Here's how each model compared in terms of mean type accuracy, mean schema compliance, and mean content accuracy:

For content accuracy with non-synthetic data,gpt-3.5-turbo outperforms all of the others and is the clear winner. Mistral is better for generating correct types and for schema compliance.
Mistral is overall better for synthetic data. We'll look at those numbers in more detail below.
In addition, Mistral is much faster than gpt-3.5-turbo. It outperformed gpt-3.5-turbo by 2x in our benchmarks.
As for Falcon? Falcon is the fastest of the three but also the least accurate.
Synthetic structured data comparison
Model name | Mean Type Accuracy | Mean schema compliance | Total incomplete items | Mean runtime / prompt (seconds) | Total cost (USD) | Group size |
|---|---|---|---|---|---|---|
OpenAI gpt-3.5-turbo | 0.85 | 0.816 | 24 | 15.004 | 0.023 | 60 |
GPT4All mistral-7b-instruct-v0.1.Q4_0 | 0.97 | 0.833 | 0 | 7.979 | 0 (Free, local) | 24 |
GPT4All falcon-q4_0 | 0.916 | 0.708 | 4 | 7.791 | 0 (Free, local) | 24 |
Here's how each model compared in terms of both completeness and type accuracy:
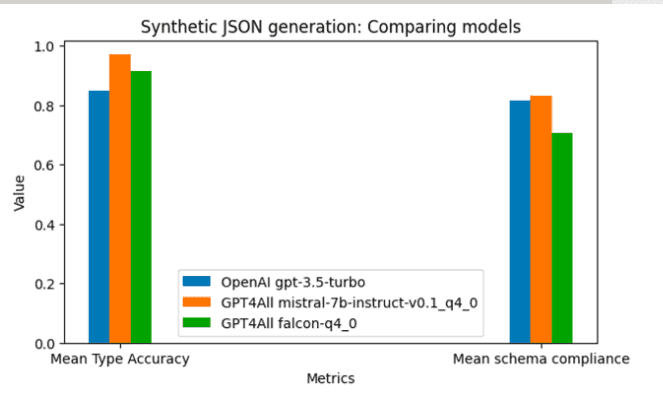
GPT4All's Mistral is the clear winner for synthetic data. It had 97% type accuracy and 83.3% schema compliance. It also outputs zero incomplete fields.
Falcon was the fastest of the models that we measured. But Mistral wasn't far behind. OpenAI lagged, taking almost 2x the time that GPT4All took.
On top of being faster than gpt-3.5-turbo, Falcon was more accurate. It generated only four incomplete items compared to gpt-3.5-turbo's 24 and had better type accuracy. However, it had the worst schema compliance.
Finally, we found that the depth of the training data used in the model mattered in terms of overall accuracy. A good example is a flight number in a synthetically generated flight itinerary. gpt-3.5-turbo knows that a flight number is a string that is a combination of a two-letter airline designator plus a 1 to 4 digit flight number (e.g., BA 322 for “British Airways Flight 22”). One of the other models accidentally generated this field as an integer.
Data conversion
Model name | Mean Type Accuracy | Mean schema compliance | Total incomplete items | Mean content accuracy | Mean runtime / prompt (seconds) | Total cost (USD) | Group size |
|---|---|---|---|---|---|---|---|
OpenAI gpt-3.5-turbo | 0.96 | 0.96 | 0 | 0.92 | 18.82 | 0.007 | 30 |
GPT4All mistral-7b-instruct-v0.1.Q4_0 | 1 | 1 | 0 | 1 | 5.71 | 0 (Free, local) | 12 |
GPT4All falcon-q4_0 | 0.6 | 0.33 | 2 | 0.46 | 5.41 | 0 (Free, local) | 12 |
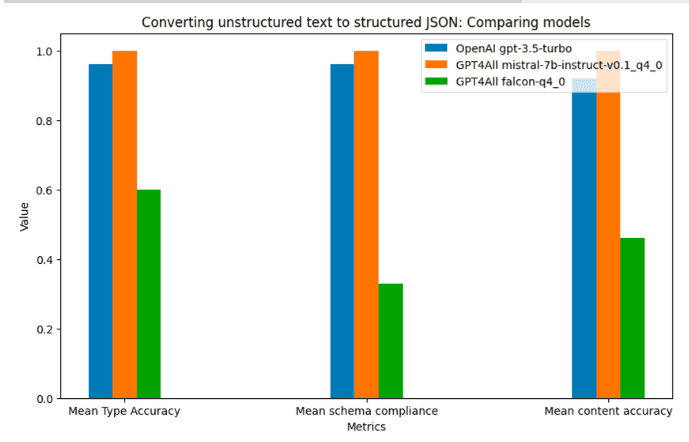
Mistral was the winner, as it was excellent at converting unstructured data to JSON. It achieved 100% accuracy on generating correct types, schema compliance and also generating correct content into each field.
However, gpt-3.5-turbo was also a strong performer and comes in a close second.
Falcon was fastest but achieved only 33% schema accuracy and 46% content accuracy.
Data filtering
Model name | Mean Type Accuracy | Mean schema compliance | Total incomplete items | Mean content accuracy | Mean runtime / prompt (seconds) | Total cost (USD) | Group size |
|---|---|---|---|---|---|---|---|
OpenAI gpt-3.5-turbo | 0.96 | 0.96 | 0 | 0.96 | 12 | 0.009 | 30 |
GPT4All mistral-7b-instruct-v0.1.Q4_0 | 1 | 1 | 0 | 0.66 | 7.75 | 0 (Free, local) | 12 |
GPT4All falcon-q4_0 | 1 | 1 | 0 | 0.389 | 7.504 | 0 (Free, local) | 12 |

The winner here is gpt-3.5-turbo. Even though it only achieved second place in schema compliance and type accuracy, it it had 96% content accuracy.
Mistral and Falcon are quite poor with content accuracy in data filtering at just 66% and 38.9%, respectively. Both achieved 100% accuracy in generating correct types and being schema-compliant. However, that's less of an important factor in filtering.
Data interpretation
Model name | Mean Type Accuracy | Mean schema compliance | Total incomplete items | Mean content accuracy | Mean runtime / prompt (seconds) | Total cost (USD) | Group size |
|---|---|---|---|---|---|---|---|
OpenAI gpt-3.5-turbo | 0.93 | 0.93 | 1 | 0.93 | 9.194 | 0.008 | 30 |
GPT4All mistral-7b-instruct-v0.1.Q4_0 | 1 | 1 | 0 | 0.66 | 6.17 | 0 (Free, local) | 12 |
GPT4All falcon-q4_0 | 0.66 | 0.66 | 4 | 0.16 | 6.32 | 0 (Free, local) | 12 |

In data interpretation, gpt-3.5-turbo again comes out on top. It achieved 93% content accuracy and was schema-compliant 93% of the time.
Mistral performed will in type accuracy and schema compliance. However, Mistral performed poorly at generating the right content for data interpretation workloads. In some cases, simple operations, such as averages, were calculated incorrectly.
Falcon performed poorly across the board in data interpretation. It even fell to the bottom in terms of processing time!
Achieving even greater accuracy in structured data
Overall, based on our tests, gpt-3.5-turbo performed the best in terms of accuracy for non-synthetic data. However, Mistral's performance with synthetic data shows that open source models for AI, like GPT4All, have a role to play as a free alternative to commercial pay-for-play models like OpenAI.
No matter which model and which workloads you run, you can increase output accuracy further by using Guardrails AI to filter and correct LLM output according to a data model. You can use Guardrails AI to reduce LLM hallucinations, increase information retrieval accuracy, and more.
Want to learn more? Try out the open-source project today.